What It Does
- Custom Ranking: Assign a rank to each row using plain-English logic—no code or SQL required
- Optional “Why?”: Flip on reasoning to include concise rank explanations
- Flexible Inputs: Rank by any column(s)—Mix and match GTM, firmographic, or behavioral data
- Clean Output: Returns your original table + a
RANKcolumn (and optionalREASON)
🏁 Getting Started
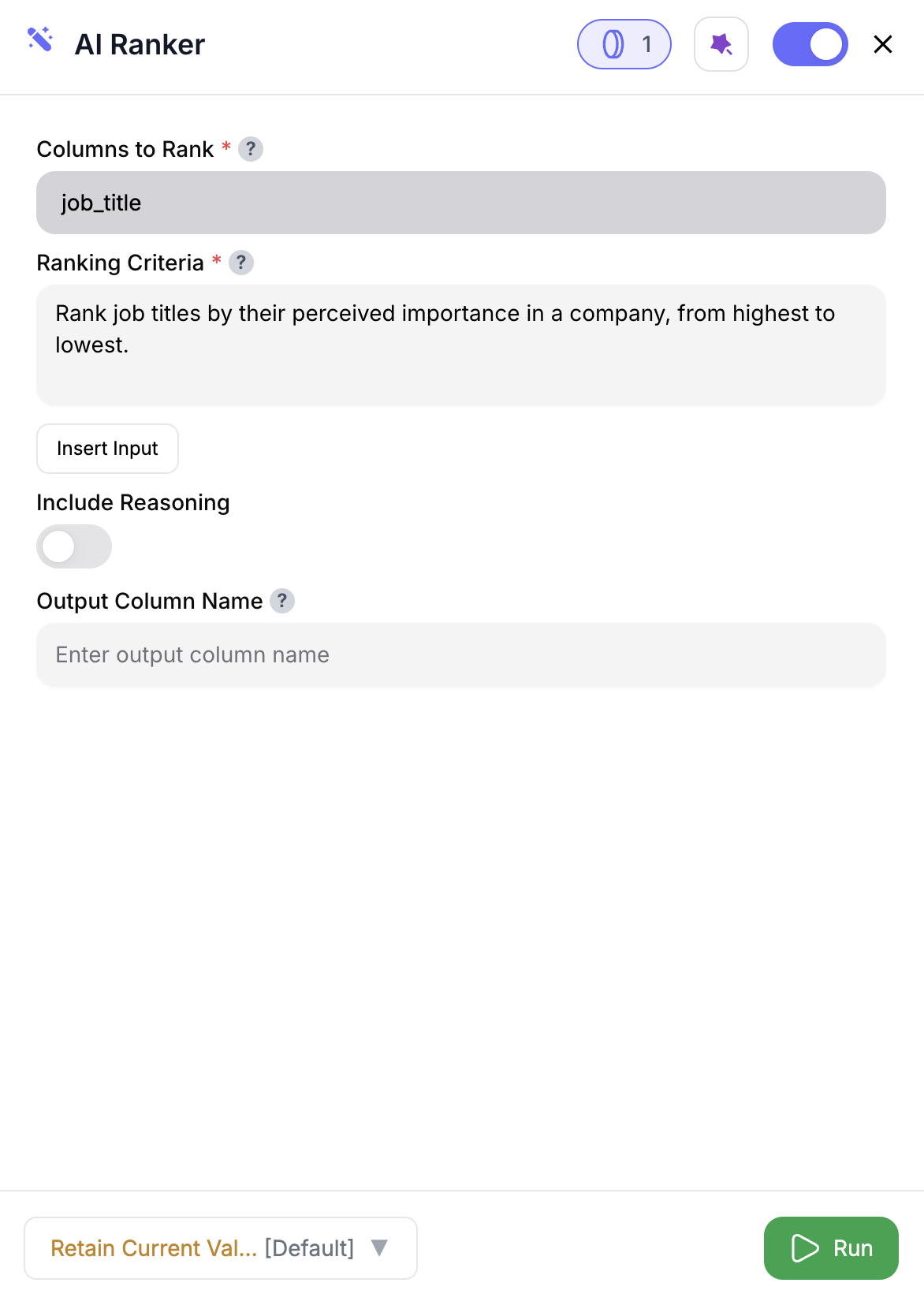
Select Columns
Pick the fields to use for ranking—like
@Close Date, @Deal Size, or @Engagement Score.Inputs
🛠️ Required Fields
-
Columns to Rank (✅)
Select the fields that drive ranking—these values get sent to the model for logic evaluation. -
Ranking Criteria (✅)
Describe your rules in plain English.
Example: “Rank by highest Engagement Score, then by newest Lead Source.”
🎯 Optional Fields
-
Include Reasoning (⚪️)
Adds a second column (REASON) explaining why the rank was assigned.
Adds 1 extra credit per row. -
Output Column Name (⚪️)
Defaults toRANK. Use a custom name likePriorityRankto avoid name collisions.
Output
RANK– Numerical value based on your rules (lower = higher priority)REASON(optional) – Short explanation for each rank
The lower the number, the higher the priority. (1 = top-ranked)
🚀 Use Cases & Prompts
| Use Case | Example Prompt |
|---|---|
| Pipeline Prioritization | “Rank open opps by soonest Close Date, then highest Deal Size.” |
| Lead Scoring | “Rank leads by engagement + firmographic fit.” |
| Account Segmentation | “Rank accounts by ARR and likelihood to close this quarter.” |
| Inventory Optimization | “Rank SKUs by highest margin, then by age.” |
✨ Pro Tips
⚠️ Important Considerations
🛠 Troubleshooting & Gotchas
| Symptom | Likely Cause | Quick Fix |
|---|---|---|
| All ranks are the same | Criteria is too vague | Add more specific thresholds or secondary conditions |
| Blank ranks | Nulls in input columns | Fill or filter missing values ahead of this node |
| Flow stalls on large tables | Too many rows at once | Pre-filter or chunk into smaller batches |
📝 FAQ
Can I rank by more than one field?
Can I rank by more than one field?
Absolutely. Just reference them all in your criteria (e.g., “Rank by ARR and Close Date”).
Can I combine this with scoring?
Can I combine this with scoring?
Yes — score first with AI Scorer, then rank using that column.
What happens if multiple rows tie?
What happens if multiple rows tie?
The model may assign the same rank. Use more precise conditions to break ties.
💰 Pricing
| Action | Credits / Row |
|---|---|
| Rank only | 1 |
| With Reasoning | 2 |
Each row you rank consumes credits. Reasoning adds +1 credit per row.
Prioritize like a pro—drop AI Ranker into your flow and always know what to tackle first. 🚦📊