Documentation Index
Fetch the complete documentation index at: https://docs.nrev.ai/llms.txt
Use this file to discover all available pages before exploring further.
What It Does
- Merges two datasets either by stacking rows (append) or joining columns (join)
- Join on row position, matching fields, or all combinations
- Supports join types: inner, left, right, outer, and cross
- Automatically resolves field conflicts and validates input compatibility
- Outputs are available in both CSV and Parquet formats
🏁 Getting Started
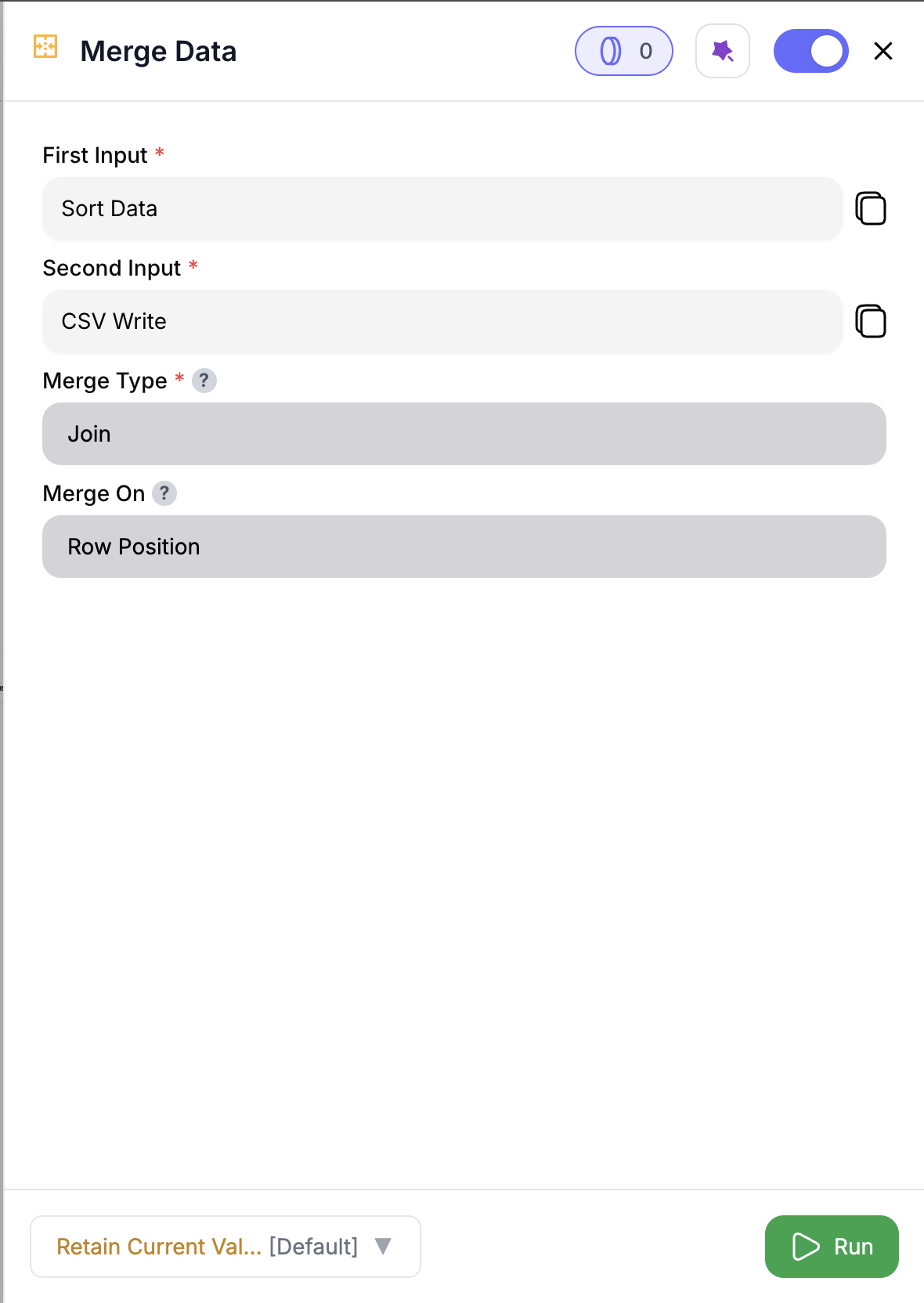
Configure Join (if selected)
Select how to join:
- Row Position: merge by row order
- Matching Fields: match shared column values
- All Combinations: cross join all rows
Inputs
🛠️ Required Fields
-
First Input (✅)
The primary dataset — acts as the left table in joins. -
Second Input (✅)
The secondary dataset — used as the right table in joins. -
Merge Type (✅)
ChooseAppendorJoin. IfJoin, you must also specify how to merge.
Output
You get a single merged dataset with:- All merged rows and columns, depending on type and logic
- File download links:
s3_output_url: Parquet formats3_output_url_csv: CSV format
- A
merge_infosummary describing how many rows were merged and how
Merge Types & Options
🔁 Append (Row Stack)
- Adds all rows from the second dataset below the first
- Columns from both inputs are preserved
- Missing columns will be filled with
null
🔗 Join (Row Merge)
- Combines rows across datasets side-by-side
- Choose how to join:
- Row Position: Merge row 1 with row 1, row 2 with row 2, etc.
- Matching Fields: Match rows using one or more shared columns
- All Combinations: Every row from dataset A is joined with every row from dataset B
Join Types (for Matching Fields only)
| Join Type | Description |
|---|---|
| Inner Join | Keep only rows where both sides match on all fields |
| Left Join | Keep all rows from first dataset + matches from second |
| Right Join | Keep all rows from second dataset + matches from first |
| Outer Join | Keep all rows from both datasets (full outer) |
| Cross Join | All combinations (used with “All Combinations” merge mode) |
🚀 Example Use Cases
| Scenario | Setup Example |
|---|---|
| Stack monthly exports | Merge Type: Append |
| Enrich Nrev AI accounts | Merge Type: Join, On: Matching Fields, Join Type: Left, Key: domain |
| Align scraped leads with CRM | Merge Type: Join, On: Row Position |
| Pair Sayanta’s leads with rep list | Merge Type: Join, On: All Combinations |
✨ Pro Tips
⚠️ Important Considerations
🛠 Troubleshooting & Gotchas
| Symptom | Likely Cause | Quick Fix |
|---|---|---|
| Output is empty | No matching rows in join | Adjust join fields or change join type |
| Unexpected nulls in output | Fields missing in one input | Reconcile columns or switch to Join |
| Merge fails | Only one input connected | Ensure both First and Second are linked |
| Duplicate fields with _1/_2 suffix | Field name conflict | Rename upstream columns if needed |
📝 FAQ
Can I append datasets with different columns?
Can I append datasets with different columns?
Yep — all fields are preserved. Missing values get filled with
null.Do column names need to match for join?
Do column names need to match for join?
Only if you’re using
Matching Fields. For other join types, names can differ.How are output columns ordered?
How are output columns ordered?
Fields from the First Input come first, then fields from the Second.
💰 Pricing
The Merge Data node is free — no credits required.
Whether you’re stacking exports or enriching accounts, Merge Data makes it seamless. Join, append, and move on. 🔗