Documentation Index
Fetch the complete documentation index at: https://docs.nrev.ai/llms.txt
Use this file to discover all available pages before exploring further.
What It Does
- Restrict rows globally or within groups, limiting dataset size.
- Optional sorting of rows based on any specified column.
- Allows selective data preprocessing (grouping keys and column to sort).
- Supports multiple grouping keys to limit rows per category.
- Graceful fallback when
limit_across_groupsis true but no grouping keys provided.
🏁 Getting Started
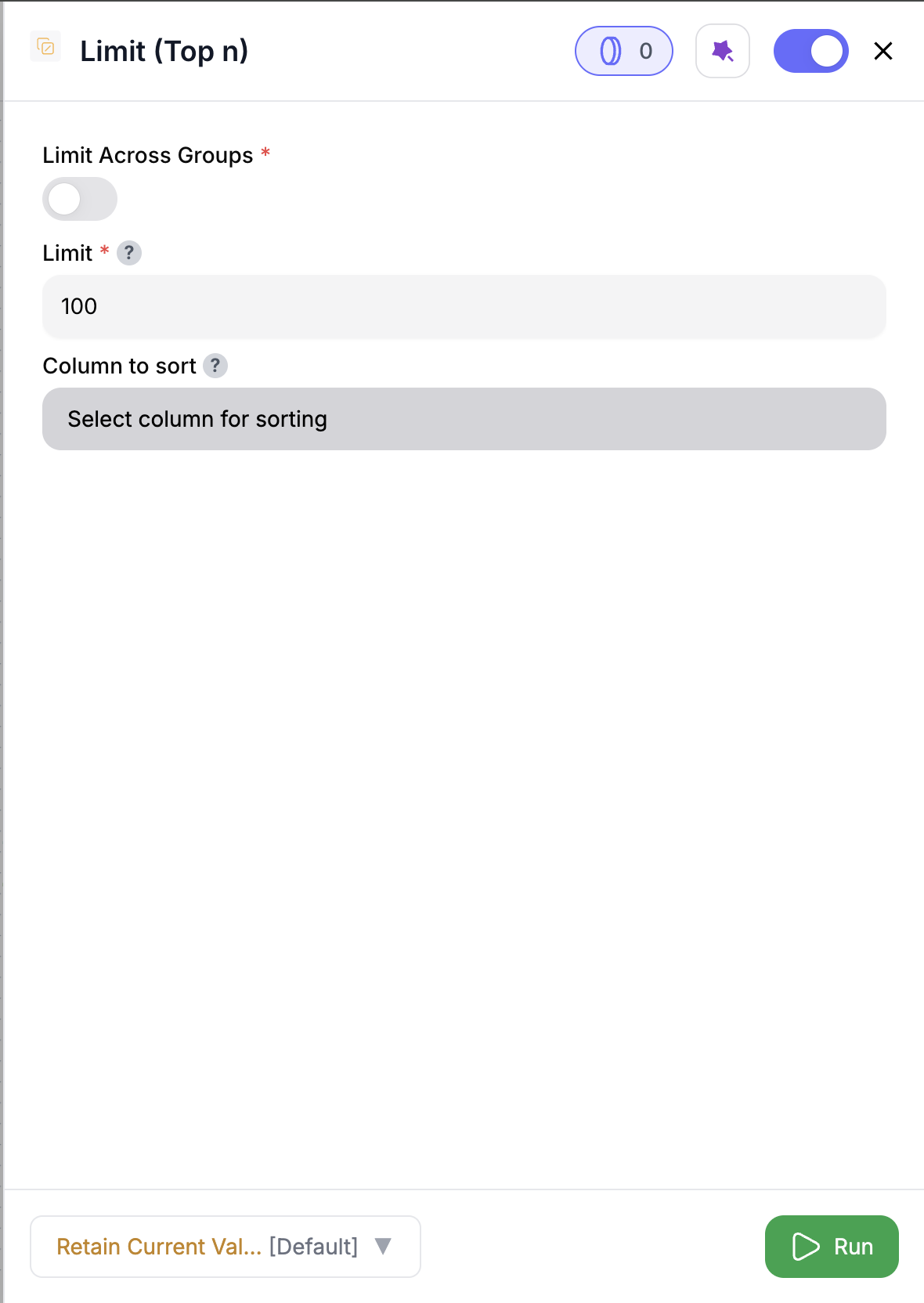
Define Limit Settings
Specify the number of rows to return, sorting options, and grouping keys if required.
Inputs
| Input Name | Type | Required | Description |
|---|---|---|---|
input_df_s3_url | Optional[str] | Yes, if template variables are used | S3 URL to the input DataFrame (CSV/Parquet). Required when using template variables in settings. |
Outputs
The node returns a List[Dict[str, Any]] where each dictionary contains:| Output Name | Type | Description |
|---|---|---|
s3_output_url | str | S3 URL of the output DataFrame (Parquet format) |
s3_output_url_csv | str | S3 URL of the output DataFrame (CSV format) |
file_info | Dict | Contains metadata: rows_count (int), columns_count (int), columns (List[str]) |
handle_condition | str | Always "_default" for this node (no conditional outputs) |
Output DataFrame Structure
The output DataFrame will contain the same columns as the input DataFrame, with the following characteristics:- All input columns preserved: No columns are added or removed.
- Row count limited: The number of rows is reduced based on limit settings.
- Selective preprocessing: Only grouping keys are preprocessed.
- Grouping keys: Converted to string format with nulls replaced by ‘(Empty)’.
- Column to sort: No preprocessing - uses pandas default null handling.
- Other columns: Preserved in original format.
- Sorting applied: If specified, rows are sorted by the designated column using pandas default null handling.
How It Works
- Data Loading: Loads input data from S3 using the data loading helper.
- Field Validation: Ensures all referenced columns exist in the input data.
- Data Preprocessing:
- Grouping keys: Converts to string format and replaces nulls with ‘(Empty)’.
- Column to sort: No preprocessing applied - uses pandas default null handling.
- Other columns: Left unchanged.
- Limit Logic Application:
- Without Grouping: Applies limit to the entire dataset.
- With Grouping: Groups data by specified keys, applies limit to each group, then combines results.
- Graceful Fallback: If
limit_across_groupsis True but no grouping keys provided, behaves as if no grouping.
- Sorting: If
column_to_sortis specified, sorts data before applying limit using pandas default null handling. - Test Mode: If enabled, limits output to 5 rows regardless of limit setting.
- Output Generation: Saves results to S3 in both Parquet and CSV formats.
🚀 Example Use Cases & Prompts
| Use Case | Setup or Prompt Example |
|---|---|
| Sampling Large Datasets | Limit to a small number of rows for a preview |
| Top N by Metric | Limit to top N rows based on a sorting column (e.g., score) |
| Grouped Limiting | Limit rows within groups (e.g., top N customers per region) |
| Performance Optimization | Reduce the dataset size for faster processing |
✨ Pro Tips
⚠️ Important Considerations
🛠 Troubleshooting & Gotchas
| Symptom | Likely Cause | Quick Fix |
|---|---|---|
| No rows in output | Missing grouping_keys | Ensure grouping_keys is set if limit_across_groups is True. |
| Unexpected column order | Column sorting issue | Verify column_to_sort and sorting_order settings. |
| No data found | Invalid S3 URL | Ensure correct S3 URL is provided for the input DataFrame. |
📝 FAQ
Can I apply a limit within groups?
Can I apply a limit within groups?
Yes, set
limit_across_groups to true and specify grouping_keys to limit rows within each group.What happens if no sorting column is specified?
What happens if no sorting column is specified?
The node will apply the limit to the unsorted data, returning rows in their original order.
💰 Pricing
The Limit (Top N) Node incurs no additional cost for limiting rows.| Action | Credit Cost |
|---|---|
| Row Limiting | 0 credits |
There is no charge for this node unless it’s used in conjunction with other nodes that incur charges.
Drop this node into your flow to efficiently limit the number of rows and optimize data processing. 🚀